Attentions!
- You must take a snapshot before that procedure;
- That procedure may cause unavailability;
Prerequisites:
- A senhasegura cluster of two nodes;
In this article, we’ll understand how to do a recovery senhasegura on scenarios of disaster.
In our scenario, we have two instances of senhasegura on cluster. We going to power off abruptly the master node and recover the secondary node when it stays on split-brain.
So, first, identify who’s your master node. Do it run the command on cli “orbit application status”.
In your secondary node, you must configure the senhasegura to accept recovery. For it, access “Orbit>Settings>Recovery”. On this screen, you must put the IP address that the button “Assume as master” is will enable and visible. That button is responsible for recovery senhasegura and it’s visible in scenarios of disaster only to users that your origin match with the IPs put in “Allowed origin IPs to perform system recovery”.
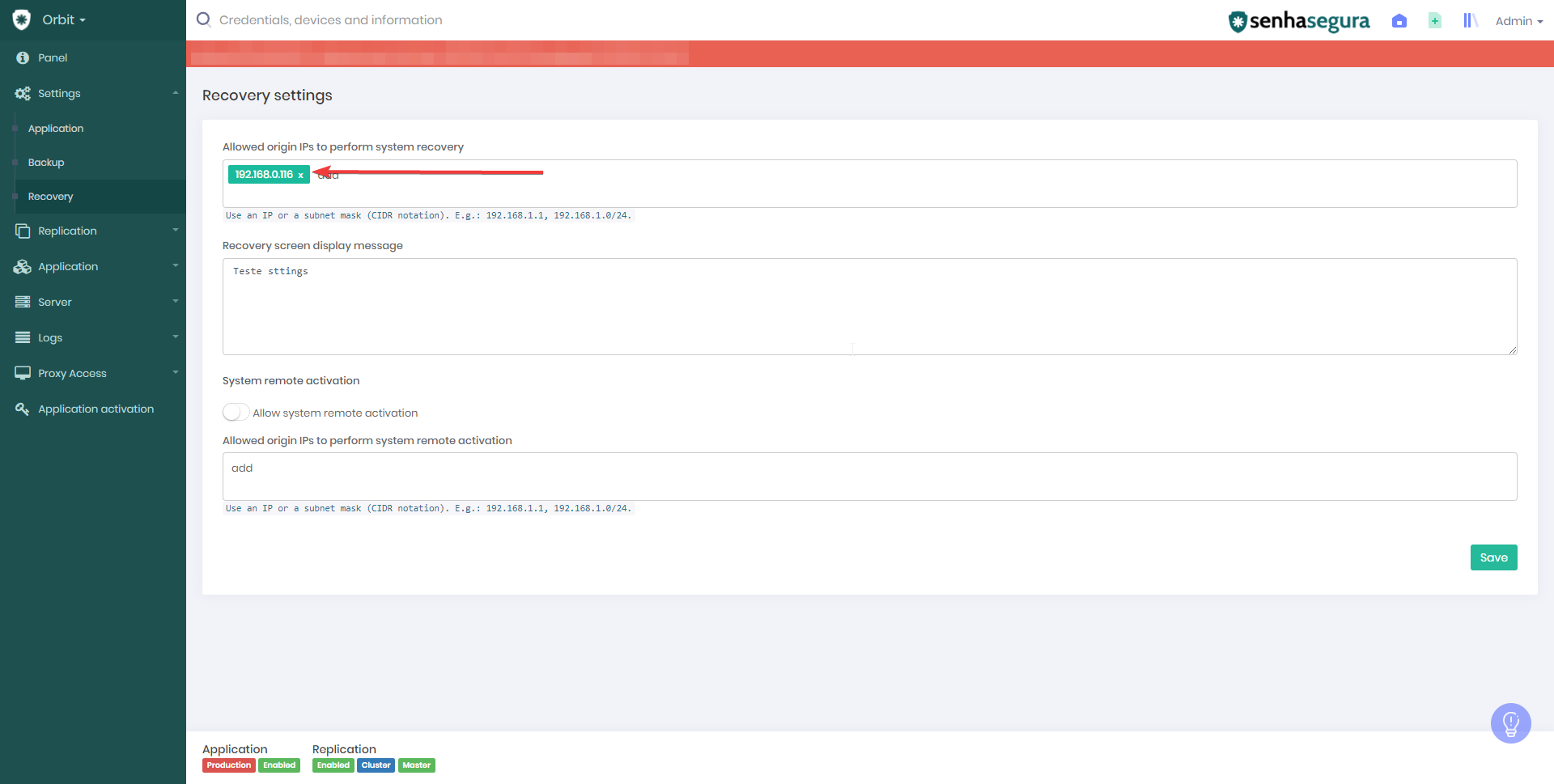
After doing it, doing the snapshot and validating that cluster is ok (Orbit>Repplication>Status>Validate Cluster size), power off in a way abrupt and wait for the secondary enter on split-brain.
After the secondary is on split-brain, the button “Assume as master” will be enabled to you. Click on it to recovery senhasegura.
senhasegura will be recovered and the application is available in some minutes. To enable senhasegura modules, go to “Orbit>Settings>Applicaiton>Enable application”. After this, log out and log in again and senhasegura is available!
When you power on senhasegura, the primary node will go synchronize to secondary automatically.
We have a great video about this scenario! Follow below.
